Visualizing Data in PostgreSQL Using Grafana
Presented by:

Preetam Jinka
Preetam is a Principal Engineer at ShiftLeft where he focuses on backend APIs and data engineering.
Observability is a core value in our engineering organization, and while we have plenty of manual instrumentation in our application code, we've found that creating visualizations directly from PostgreSQL data gives us a whole new approach to improving system observability. Using PostgreSQL as a Grafana datasource allows you to directly visualize the source of truth instead of depending on application metrics, which can be imprecise due to sampling, averaging, loss of dimensionality, or even impossible if metrics need to span multiple services. It also lets you leverage of data we already have, and create dashboards independent of the usual development and release cycle.
For example, let's say you have a users table which stores user data along with a created_at timestamp. You can create a chart to visualize users created over time using just Grafana and PostgreSQL. Furthermore, you can create alerts on this metric so you'll get notified when there is a sudden increase in new users created. All of this can be done without writing and deploying a single line of code in your application.
In this talk I will cover
- What kinds of data in PostgreSQL can be visualized in Grafana (spoiler: anything with a timestamp column, and more!)
- Several examples of visualizations and the SQL to make them
- Tips for designing your schemas so you can take advantage of visualization capabilities in Grafana
- Setting up alerts
The examples I will be demonstrating include
- Time series
- Batch process task metadata
- Queueing system data
- Generic SaaS data (users, billing information, etc.)
Examples of charts created directly from PostgreSQL tables:
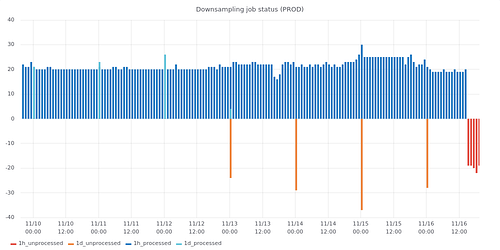
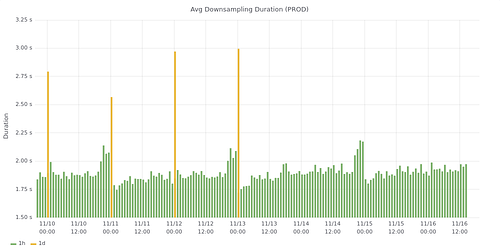

- Date:
- 2019 March 21 15:20 EDT
- Duration:
- 20 min
- Room:
- New York Ballroom West
- Conference:
- Postgres Conference
- Language:
- Track:
- Ops and Administration
- Difficulty:
- Medium