The future of community in light of Babelfish
(adapted from PGConf NYC 2021 Keynote)
Ryan Booz
Director, Developer Advocacy
Timescale
Twitter: @ryanbooz
Email: ryan@timescale.com
On December 1, 2020, at its annual re:Invent conference, Amazon AWS announced Babelfish - an open source PostgreSQL translation layer that allows SQL Server applications to work natively, and transparently, with PostgreSQL. To be honest, as someone that's spent a significant part of my career using both SQL Server and PostgreSQL, this wasn't actually a very “exciting” development.
I'm not sure that most people in either community really gave it that much notice a year ago. In fact, my first thought was that Babelfish is just an oversized Object-Relational Mapping (ORM) framework that wasn't tied to any specific development language. While these tools have proven to be hugely useful to many developers, nearly every DBA has first-hand war stories that demonstrate the challenge that automated query generation can impose on a complex system. Frankly, the thought terrifies me a bit.
Until recently, however, all we knew about Babelfish was based on Amazon published content. But in October 2021, Babelfish was finally released for public access and preview at https://babelfishpg.org/.
Not long after the release was announced, I had the opportunity to participate in a video call with some members of the European PostgreSQL community for a first look at Babelfish in real life. It was interesting, and kind of exciting to see what worked and what didn't. However, I didn't leave that call any less concerned about the struggles my SQL Server friends will have as their management teams mandate switching to PostgreSQL using Babelfish. It also got me thinking - why SQL Server?
I decided to look at DB-engines.com to see if the engagement metrics that they track would shed any light on it. Although the website doesn't disclose the specific method for determining database engine rank, we know that social engagement and search engine trends play a role in the rankings.
When I zoomed in on the four "major" relational database engines, utilizing the last 9 years of data, two things jumped out at me.
- Only PostgreSQL has seen consistent increases in popularity and engagement over the 9 years of tracking
- While the three other engines have had some steady decline over the same period, SQL Server seems to have the biggest drop off compared to Oracle and MySQL
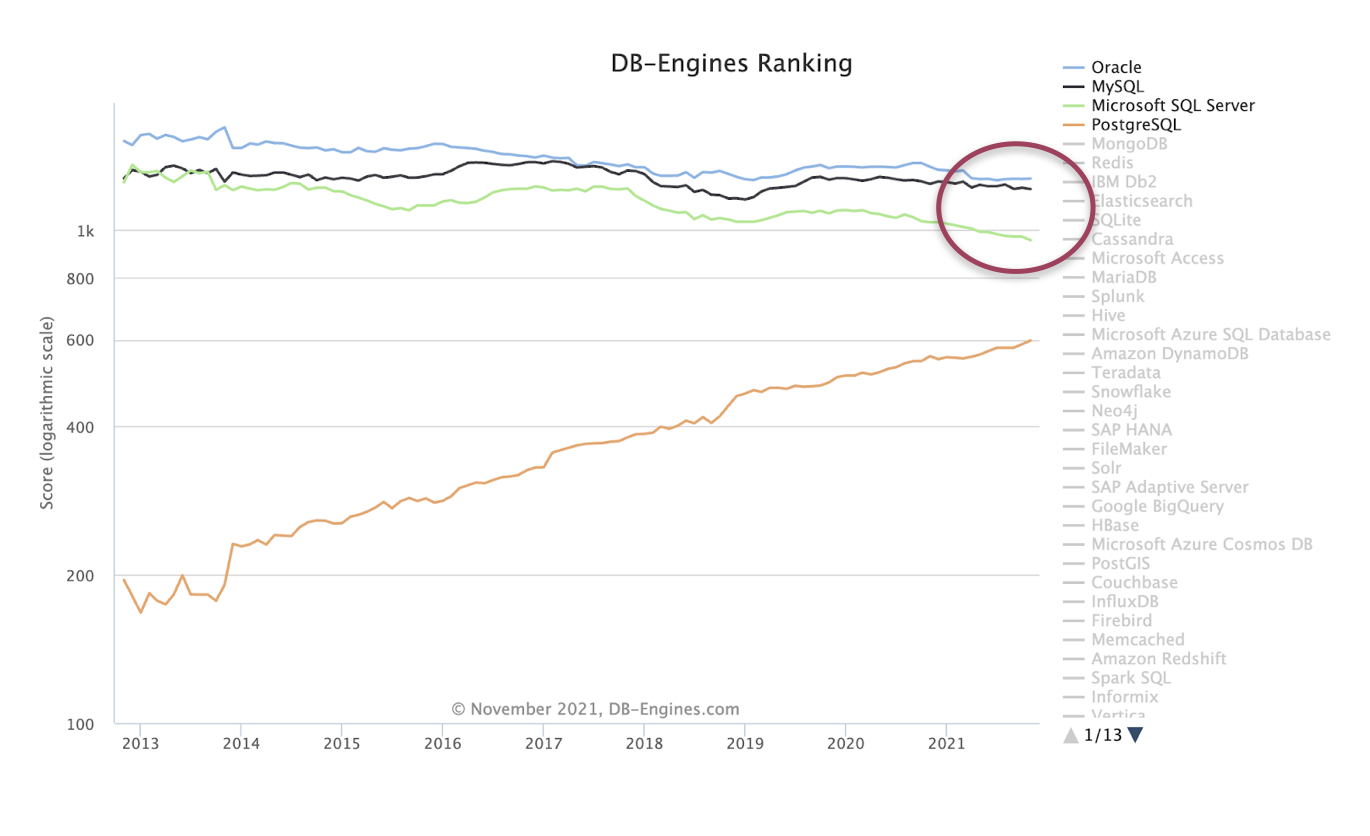
While I can posit many reasons why Amazon AWS chose to go directly after SQL Server for this transparent compatibility tool, the reasons to use PostgreSQL as the solution to the problem is obvious to the PostgreSQL community. PostgreSQL:
- is the fastest growing, relational database engine on the planet
- has a proven foundation
- is easy to enhance through extensibility
Regardless of how we feel about this new turn of events or the potential onslaught of new support needs by users of SQL Server, there's not much we can do about it. The proverbial cat is already out of the bag.
Whether the necessary patches are included in the core PostgreSQL code or not, AWS Aurora, at least, will still offer this functionality as a service. I believe this means that over the next 2-4 years, the community will grow from a base of users that have a lot of database experience but have little footing for how to approach a similar, but different, database. And regardless of how we feel about the new demands, this will put on this community, it's a group of people that still want to do their job well and contribute back to the community.
Why do I care?
So, why do I care? Well, if you were to put my 20+ years of database experience into a word cloud of sorts, SQL Server would occupy the largest portion of space. For nearly 15 of the last 21 years, I was primarily a Microsoft data platform user. And while PostgreSQL has occupied the second largest (and longest) portion of my database landscape, I really came of age as a database professional within the SQL Server community. In fact, since coming back into the PostgreSQL community almost 4 years ago, I've continued to look for ways to foster a community and learning modeled after what I knew and experienced through SQL Server and the Professional Association of SQL Server (PASS) community. And I can say, without a doubt, that I'm not the only one looking for the same thing.
Let me ask you something then.
When was the last time you had to join a new community?
Is the first thing that comes to mind a technical community (data, programming language, visualization tools, etc.) or something else? Whatever community that was, how did you feel after first stepping through the proverbial door?
Did you have a crowd of people ready to cheer you on, eager to see you succeed, and ready to support you?
Or, did you feel like an outsider looking in, trying to figure out how to find the right help, from the right people? Did you feel like everyone else always knew how to connect with the people around you but you struggled to find comradery and resources?

Depending on where you fall, what could have made it better for others or for yourself?
Let's bring this same thought experiment a little closer to home. What about the PostgreSQL community? What was your "onboarding" experience like and how does that compare to some of the newest members you've met recently?
It just so happens that we have some feedback from the larger community based on The State of PostgreSQL survey Timescale orchestrated this past April. There were 500 respondents that ranged in experience levels from novice, newly joined developers, to users with 20+ years of experience. Of those 500 respondents, 49.5% have used PostgreSQL for 5 years or less, and 50.5% had PostgreSQL for 6 years or more.
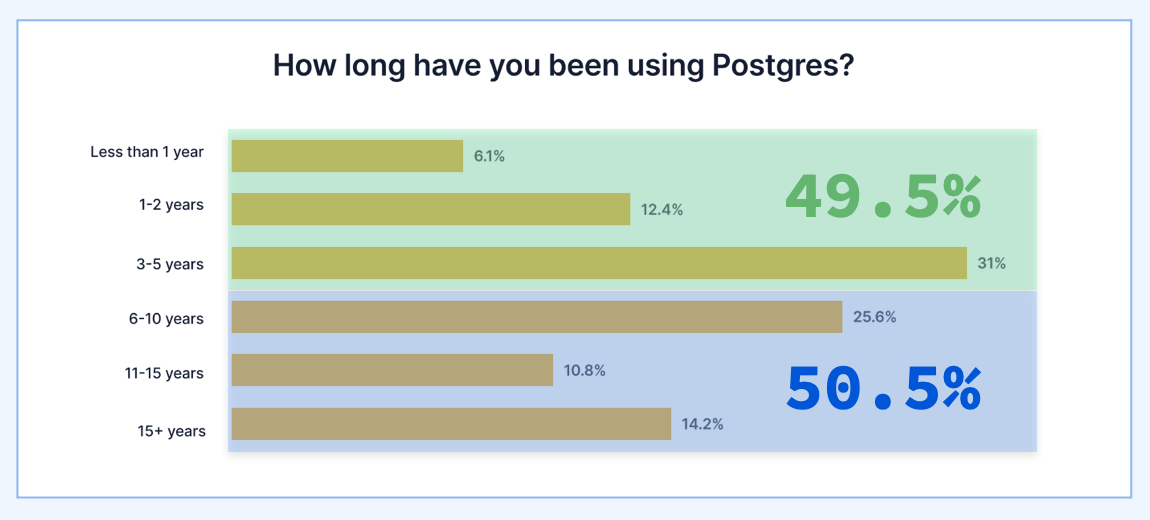
It would make sense, then, that about 50% of the survey participants felt like it was a bit difficult to use PostgreSQL and get involved with the community.
And yet, the other 50% of participants seem to have a very different experience with PostgreSQL the longer they stay connected.
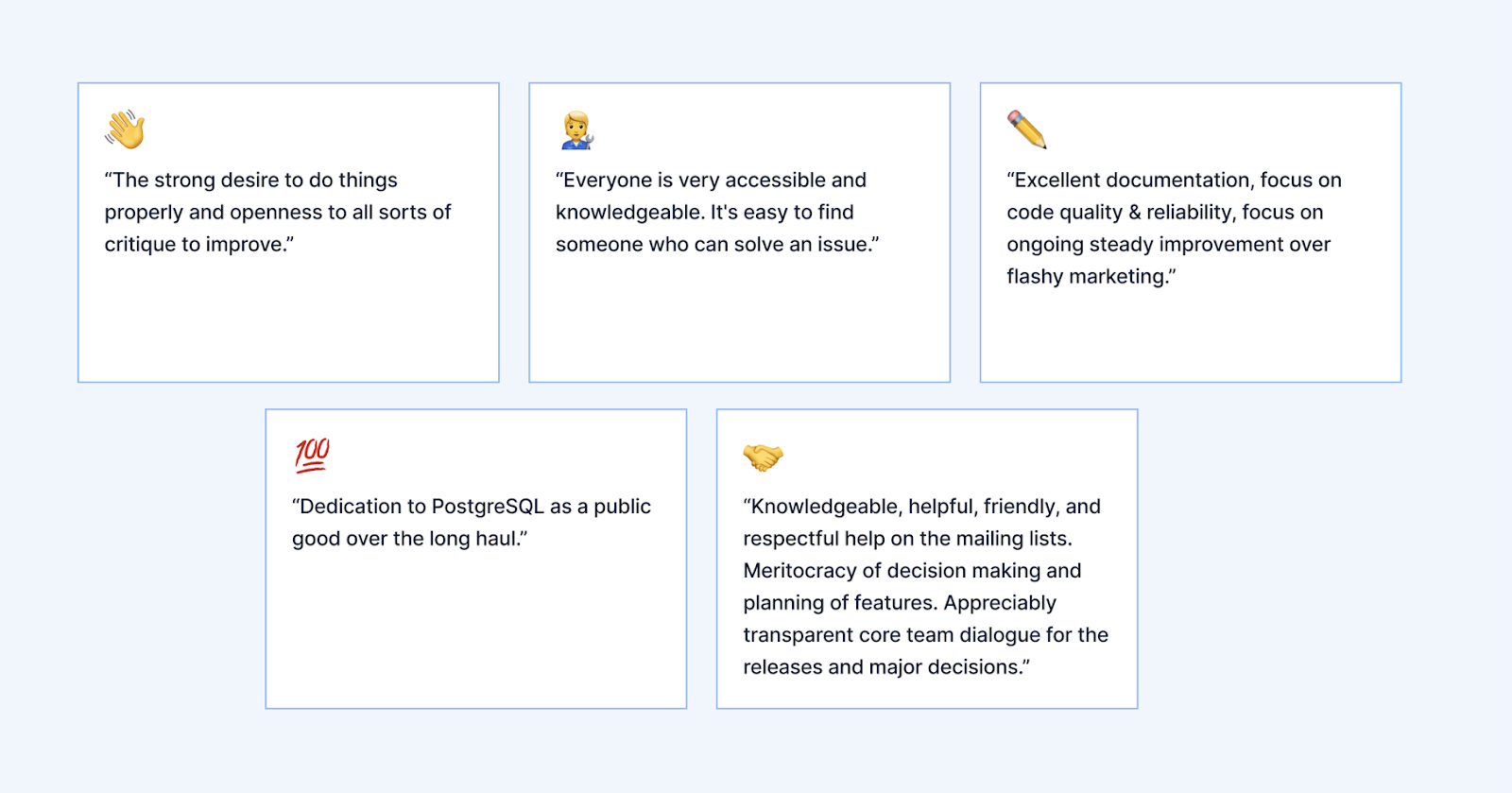
The real goal, then, is to determine ways to improve the user experience within the PostgreSQL community earlier in the cycle, rather than hoping folks stick around for more than 5 years so that they can begin to have a more positive outlook on the community at large.
As a Developer Advocate at Timescale, one of my primary responsibilities is to engage with the PostgreSQL community so that we can figure out how to tackle these issues head-on. I'm excited to contribute to the efforts, learning better methods to teach people how to use this technology well and help them be successful.
And, as a former SQL Server professional and community member, I want to prepare for what I believe will be a growing number of database professionals joining the Slack channel, Twitter conversations, and conferences trying to improve their craft and give back to the community.
To do this, we have at least two options in the months and years ahead.
The first option is to take sides. Unfortunately, this happens all too often in technical communities. Whether it's a database engine or the newest development language, this approach is an option. "We're better! You're not!"

Or… we could choose to just sit around the table, share a meal, and learn from one another about how we can build a better, shared community based on the best parts of what each community offers.

Quite honestly, we could ensure that we're treating the community more like our beloved namesake - Slonik the elephant.

It turns out that Elephants are close-knit communities. They care for each other, they actively accept orphans and elephants that are in need, and they're generational - passing down knowledge and community expectations from one generation to the next. Not a bad example to follow, right?
Five initial options for building a better PostgreSQL community
Let me present you with 5 quick, high-level thoughts on ideas we could reuse from the SQL Server community that might begin the process of improving participation and engagement.
(1) Lead with empathy and curiosity
What does it mean to lead with empathy and curiosity? When the posture of the community starts with empathy, it means that we remember what it was like to be new to a community ourselves. When we start conversations from a place of curiosity, we avoid choosing sides and instead join new users where they are. Here are a few things to keep in mind in regards to the SQL Server community that might start to show up in greater numbers soon, although I think these are good things to remember regardless of the user.
Expect confusion from users that already know SQL. Oftentimes these users honestly don't know that the dialect of SQL they've been using (T-SQL in this case) isn't a standard. They know concepts but not direct comparisons to the SQL standard or pl/pgsql.
Remember that you were a newbie once. Remember when I asked you to think of the last new community you joined? ;-)
Assume positive intent and that they have tried to search out a solution first. Again, many users coming from the SQL Server community have a good network of people and resources they've grown accustomed to (we'll touch on that next!). But that community has also fostered good habits for finding solutions and asking better questions. Assume the best!
Prepare resources to meet their specific needs. This doesn't mean that we craft all documentation, blogs, and help forums for a specific user base. But, if we know many people will be joining this community with the same understanding of a feature or topic, we can provide them a better foundation for transferring their knowledge into PostgreSQL. It would reduce support overall and foster better community involvement.
Let me give you one really simple example from my own experience (and that of many SQL Server users that try PostgreSQL for the first time).
It is a common practice in nearly every T-SQL script I've written, seen, or used to create and use variables and control logic directly in the flow of a script. Because all SQL is executed by default as T-SQL, there is no need for code blocks to do data-specific logic. This really simple T-SQL example is incredibly common in the day-to-day workflow of a SQL Server DBA or developer.

In PostgreSQL, however, I can't do this in the midst of my migration scripts or maintenance tasks directly. This was a constant source of frustration for me during the release of my first feature at a new company that was using PostgreSQL (but had very few developers that understood databases). I knew what I wanted to do, but I couldn't get any IDE or migration script to do what I wanted.
Eventually, I found a post that talked about anonymous functions within a SQL script for ad hoc processing. Although I didn't like the added complexity, I could finally write my migrations correctly.

Having proactive examples in the documentation that acknowledge this difference could be a game-changer for developer success.
(2) Lower the bar for entry-level #pghelp
More than 10 years ago, someone in the SQL Server community had the idea of using #sqlhelp Twitter hashtag to provide help. At the time, the size limit for a tweet was 140 characters so they understood it could only provide short, really succinct triage-like help. In some ways, I think this limitation has actually helped the community learn how to ask better questions that will draw valuable answers. This is evidenced by two things in my opinion.
First, not every question gets an answer. It's a community-led initiative and so the quality of the question and respect for the "free" nature of the help influence overall engagement. And second, the SQL Server community actively protects the use of this hashtag. That's not always taken kindly by outsiders, and I'm not even sure how much I agree that a community can "own" a hashtag, but it produces valuable community around a specific technology that has proven to be helpful for thousands of users over the years.
Like the PostgreSQL community, SQL Server users also have a community Slack channel that is active and more long-form. But today, more than 10 years after the community started using it, #sqlhelp is an active channel of connecting with the larger community to give and receive timely help.
Could we do something similar with a #pghelp hashtag?
(3) Support new members by cultivating more leaders
As the PostgreSQL community grows, we can only support users if we build a growing group of leaders. A few of the leaders in the SQL Server community realized this same need over a decade ago and proactively sought ways to build new leaders, content creators, and community advocates. One successful example of this is an initiative called "T-SQL Tuesday", a worldwide monthly "blog fest".
The idea is simple. Each month, someone volunteers to be the host, they announce the topic at least a week in advance, and then anyone from around the world can contribute to the conversation by publishing a blog on that topic. Some of the topics are technical (replication, HA, query tuning success), while some are more soft-skill-focused (best/worst SQL interview experience, how to avoid burnout in the SQL field).
As I said, it was specifically started as an initiative to get more people in the community to contribute to the conversation. Of almost any initiative that this community has undertaken in the last 10-15 years, T-SQL Tuesday has done more than anything else to cultivate new community leaders, alter careers, and bring collaboration across the globe. The most intriguing part of this for me is that it's free to run and participate in, and Microsoft has had nothing to do with it. It is completely community-led.
Starting in April 2022, a few PostgreSQL community members are going to start "PSQL Phriday", a monthly community blogging initiative. To learn more about it, the monthly topics, and how you can participate, watch the blogging feeds at planet.postgresql.org and monitor the #psqlphriday on Twitter. I'm excited to see this get started and can't wait to learn from many others in the community!
(4) Seek leaders proactively
As new members join the community and it grows, many of them will come with a desire to contribute in some way. Some of that has happened in meaningful ways around tooling that have dramatically improved the day-to-day tasks of every SQL Server DBA.
One of the best examples of this in recent years has been the DBATools project. This is a PowerShell toolkit of hundreds of commands that can help backup a database or migrate an entire cluster of servers, no UI necessary. It is heavily supported by the community and they're always looking for opportunities to grow, learn, and contribute. Finding these developer-focused initiatives could be a great way to enlist help and add additional support resources as the community grows.
(5) Develop Consistent messaging around community
Lastly, I think it would be helpful to consider ways to consistently articulate the best methods and practices for accessing help within the PostgreSQL community. Although the Community page on the PostgreSQL.org website does list many avenues for getting help, it still requires a fair amount of cognitive load to figure out which avenue is best suited for a given need.
- When do I use the email lists? What if I don't want to subscribe long-term?
- If I join the Slack channel, how do I best ask for help? Can I mention specific people to try and get help? Create new rooms?
- Why would I use IRC or Discord over Slack?
- Is there a #pghelp Twitter hashtag, and if so, what kind of questions are best asked there?
As a new user in the PostgreSQL community, I wanted this kind of guidance because I didn't want to overuse a resource or direct questions to the wrong group of people. If we had more consistent guidance on how to interface with the community across the plethora of channels, then other leaders within the PostgreSQL community could give the same consistent message. I appreciate how leaders like Brent Ozar, a leader in the SQL Server community, doesn't feel obligated to answer every question thrown their way. They have clear instructions on their blog that describe the best ways for someone to actually get effective help and they often direct them there. "Hey, thanks for reaching out. That sounds like a great question for #sqlhelp. Check out this link for instructions on how to use it!"
When people feel heard, they're more likely to stay connected and involved. Even if the answer often points them to good documentation of how to get help, they're still acknowledged and included.
Wrap up
I'd like to leave you with a small twist on a common adage.
"You can't pick your family… but you can influence who becomes your friends."
As this community grows, are we prepared to provide some new ways of engaging with them? These specific ideas might not all fit within the PostgreSQL community, but I'd be interested to hear your thoughts about ways we can better incorporate the skills and talents of the community we already have to prepare for the future. Feel free to reach out to me on Twitter (@ryanbooz), through email (ryan@timescale.com), or in our Timescale Slack channel (https://slack.timescale.com).
One last thing! The 2022 State of PostgreSQL survey will open later this spring. Take some time to review the results from last year, and then sign up at the bottom of the report to be notified when the new survey is ready. The more feedback we receive, the better we can understand our community, what's working well, and what can be improved in the years to come.