A database such as PostgreSQL is not just there to store data – it is also a tool to protect data. Your data must not be lost and it must not be seen by people who are unauthorized or hostile. The main goal is therefore to protect data at any cost and ensure that nothing is ever lost, leaked or compromised. As we have seen in the past more often than not a leak can easily ruin the reputation of a company or even lead to its destruction. This is true in all sectors including but not limited to finance, medical services, IT, and so on.
Protecting data at various levels
If you are using PostgreSQL you can protect data at various levels. The goal is to develop a comprehensive security concepts which protects from all kinds of attacks. The following aspects have to be taken into account:
-
Network security
-
Transport encryption (SSL, etc.)
-
Database level permissions
-
Data masking and obfuscation
-
Data-At-Rest Encryption (PostgreSQL TDE)
The following overview shows how to implement a sound policy at every level.
Ensuring network security
The first line of defense is always the network. The golden rule is: Only listen on network connections you really need and which offer a small attack surface. Fortunately, PostgreSQL has all the means to ensure security at this level.
The first thing to do is to configure the “listen_addresses” parameter in postgresql.conf. It tells PostgreSQL which bind addresses you want to use. The rule is: If you don’t have to listen on certain IPs don’t do it. To ensure security only use bind addresses which are really in use.
The second line of defense is pg_hba.conf. This config file will tell PostgreSQL how to authenticate which network segment. pg_hba.conf will be familiar to most readers so I will skip the details in this post.
However, let us assume that an attacker somehow manages to reach your database and launch a brute force attack to figure out your passwords. One way to defend against such an attack is to use the “auth_delay” extension which is part of the PostgreSQL contrib package. What is the general idea behind this extension? If an attacker launches a brute force attack auth_delay will wait some time before returning an error. This simple method will already greatly reduce your risk. Here is how it works:
# postgresql.conf
shared_preload_libraries = 'auth_delay'
auth_delay.milliseconds = '500'
Just add those lines to postgresql.conf and the module will take care of the rest.
Implementing transport encryption (SSL, etc.)
Once we have secured bind addresses and reduced the risk of a brute force attack it is important to protect your lines of communication. The way to do that is to use SSL. PostgreSQL supports various levels of SSL. The following levels are supported:
-
disable: I don't care about security, and I don't want to pay the overhead of encryption
-
allow: I don't care about security, but I will pay the overhead of encryption if the server insists on it.
-
prefer: I don't care about encryption, but I wish to pay the overhead of encryption if the server supports it.
-
require: I want my data to be encrypted, and I accept the overhead. I trust that the network will make sure I always connect to the server I want.
-
verify-ca: I want my data encrypted, and I accept the overhead. I want to be sure that I connect to a server that I trust.
-
verify-full: I want my data encrypted, and I accept the overhead. I want to be sure that I connect to a server I trust, and that it's the one I specify.
Depending on your performance and security requirements you can decide which level is best for you. Performance-wise SSL encryption does not come for free but if your security requirements are high it is worth paying the price.
Configuring database level permissions
Once you have taken care of network security, pg_hba.conf, authentication, as well as transport encryption it is time to take a look at what you can actually do inside the database.
The following layers of security are important:
-
schema: Make sure that only trusted people can access a schema
-
table: Ensure that only relevant people have access to a specific table
-
column: Restrict access to columns for specific users (to protect credit card data and alike)
-
row-level-security (RLS): Remove rows from the scope of a user
RLS (row-level-security) is especially important and promising because it allows people to only access specific rows in a table which greatly increases your ability to protect data in a very fain grained way. The important thing to keep in mind is: RLS is powerful but it requires proper testing. Some stuff is quite tricky and requires a fair amount of expertise as shown in my blog post about the topic (https://www.cybertec-postgresql.com/en/postgresql-row-level-security-views-and-a-lot-of-magic/). If you need assistance with RLS feel free to get in touch with us. We are pleased to help.
Data masking and obfuscation
Studies have shown that many attacks come from within. Consider the following scenario: You are running a large online shop. Your production database is secure and nothing happens. However, your development team has to test new stuff and needs data to ensure high quality standards. What are you going to do? Do you really want to give all your developers a full copy of all your data? The trouble is: If there is no proper test data your applications will be buggy – if you hand over all your data to developers you might face issues on the legal side of you are running the risk of giving data to people you cannot fully trust under all circumstances.
The solution to the problem is Cybertec Data Masking (https://www.cybertec-postgresql.com/en/products/data-masking-for-postgresql/). Our product will allow you to define an obfuscation model and give developers access to an obfuscated dump which can be used safely. The advantages are that the data given to developers has the same properties as the live data but does not contain personal or business critical data which should not be seen by ordinary developers.
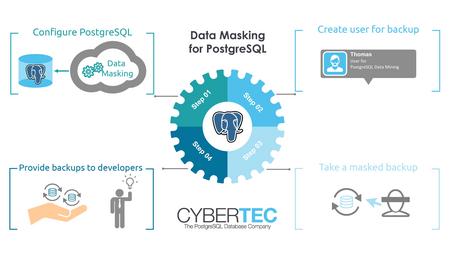
Cybertec Data Masking provides some addons and extensions to PostgreSQL and helps you to obfuscate data in the most simple and elegant way possible. Get in touch with our sales team to find out more.
Enabling Data-At-Rest Encryption (PostgreSQL TDE)
Once you have secured your database using the steps outlined above you might still be faced with additional risks. What if your disks are compromised? PostgreSQL TDE (“Transparent Data Encryption”) will be the solution for you.
PostgreSQL TDE is a PostgreSQL distribution by Cybertec which automatically encrypts data on disk. All data files are safely encrypted and unless you know the key there is no way to launch your server. PostgreSQL TDE is especially useful if you are dealing with medical records, customer and financial data, which requires even more protection and security. PostgreSQL TDE is the ultimate solution to most high end security demands.
How does it work?
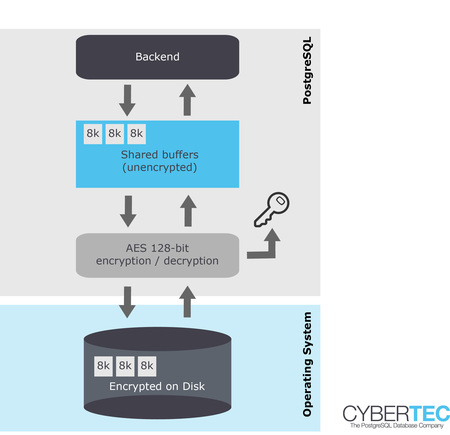
PostgreSQL will cypher every block as it is written to disk and decrypt data as it is read from your storage devices. Using cutting edge hardware acceleration TDE ensures superior performance and total transparency. PostgreSQL TDE can integrate into professional key stores and there is no need to store the key on the same server as the data.
If you are looking for PostrgreSQL TDE for PostgreSQL 11 or maybe even PostgreSQL 12 get in touch with our team here at Cybertec to find out more and to learn about this wonderful product:
https://www.cybertec-postgresql.com/en/products/postgresql-transparent-data-encryption/
(Author: Hans-Juergen Schoenig)










